
The Problem
The hotels team at Webjet got tasked with developing a new auto complete feature for our site, that would be capable of sub second suggestions across thousands of cities, localities and areas, and be smart enough to figure out near matches.
The system we had currently that was part of our monolith was a very basic text based query engine that was not very performant, and very rigid in what results it returned.
Given our technical direction, to split out our monolith into Microservices, we had an opportunity to come up with an innovative way to solve the problem. Our initial reaction was to implement an Elastic search engine, but after further exploration we decided to try out Azure’s Pass offering, Azure Search. In theory would give us similar features, without the extra effort of managing the search system.
The three MVP features that were critical to our service were:
- Result prioritization
- Fuzzy logic to cater for spelling mistakes and near matches
- Synonyms
Staying Relevant
Azure Search has a Suggestion API feature (https://docs.microsoft.com/en-us/rest/api/searchservice/suggestions), but we decided not to use it as it was not very flexible, with limited options when it comes to search result prioritization and “fuzzy” search terms with spelling mistakes.
With the Suggestions API not meeting our requirements, it was back to the drawing board, attempting to query the Azure Search API directly. To start off with, we tried querying the underlying Lucene index with just a Lucence wildcard search:
https://somesearchservice.search.windows.net/indexes/areas/docs?api-version=2016-09-01&search=mel*
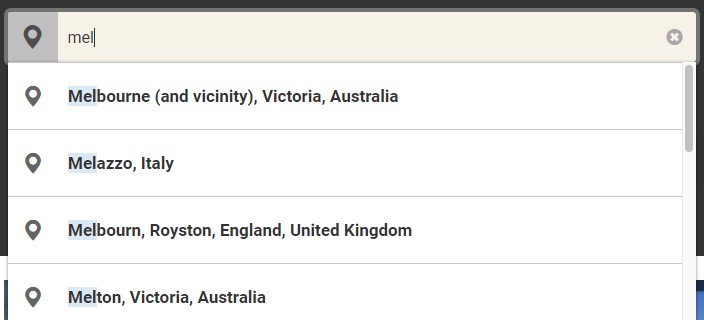
While this worked well and returned a list of destinations, it wasn’t context aware, and did not prioritise the results. A search ‘mel’ returned:
- Mele, Vanuatu
- Melle, Germany
- Melazzo, Italy
- Melaya, Indonesia
Wait! Where is the most liveable city, Melbourne???
Melbourne, Victoria, Australia couldn’t even make it to the top 4. We wanted the ability to prioritise certain destinations based on sales volume and other business decisions. To enable custom priorities, we needed to use Scoring profiles. Scoring profiles are a way to boost or decrease the value of @search.score, which determines how relevant the result item is to the search term.
We added an additional field to our search called priority, a numeric value, scoring important destinations with a low value and less important destinations with a higher value. We then set up Priority field to boost the search relevance score for those destinations.
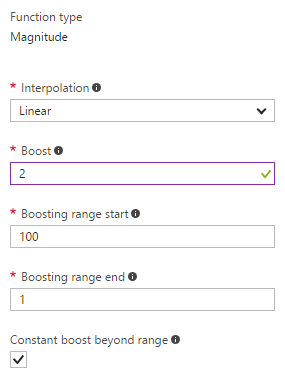
The maximum we want to boost is 2 and the linear interpolation here means the closer the priority to the end of the range, the more weight we want to throw in the score. As a result, the following call gives us Melbourne as the top match.
https://somesearchservice.search.windows.net/indexes/areas/docs?api-version=2016-09-01&scoringprofile=priorityprofile&search=mel*
Catering for User Mistakes
The second feature that needed is fuzzy logic. This would allow us to still return relevant results even if the user has made a spelling mistake or typo. For this, we first looked at using the Edit Distance based fuzzy search query capability built into the underlying Lucene search index. To do a fuzzy search, we specify the edit distance in each search term. For example, “sydbey~1” can match “sydney”.
This is what we’re after, however, it comes with some limitations:
- The maximum Edit Distance you can set per query is 2, which means the search term can have a maximum of 2 mistakes to still be considered a match.
- Edit Distance based fuzzy searching takes a huge hit on search performance.
As we needed to cater for multiple spelling mistakes and sub second response was critical fuzzy searching off the table we considered other ways we could cater for our needs of handling spelling mistakes.
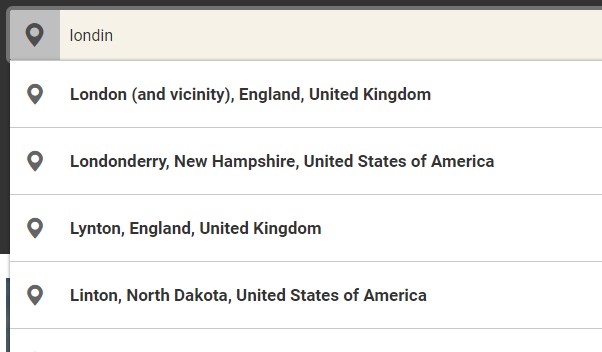
We came across Custom Analysers (https://azure.microsoft.com/en-au/blog/custom-analyzers-in-azure-search/) which could handle simple fuzzy logic, and decided to give it a go. We created a phonetic analyser which consists of a standard tokenizer and the phonetic token filter. This custom indexer builds an indexer of all possible tokens of a word based on how the word could be pronounced. This feature would cover a much wider scope of mistakes, rather than just handling one or two typos. We now can handle cases where a customer simply is unsure of the spelling. With this combination, typos such as londno, londin, melborn and koala lamper are resolved to their expected destinations (London, Melbourne and Kuala Lumpur) with very little hit on performance.
Optimizing for Performance
With our search finally achieving the search results that we expected it was now time to tune the performance. We didn’t realise when we started, but performing wildcard queries against a Lucene search index takes a huge hit on performance.
Detailed in the above blog from Microsoft was the use of Lucene EdgeNGramAnalyzers. This custom analyser is ideal for searches where you are performing a partial word search such as our customers would be doing. The indexer tokenizes each word of our destinations into all combinations of its prefixes. For instance, “Melbourne” will be indexed as the separate tokens which cover all partial spellings of the word, ie: [m, me, mel, melb, melbo, melbour, melbourn, melborne].
With each of these tokens now stored in our index we can drop the wildcard from our query simplifying the query and making it more effective. Each the search can just perform a lookup of these tokens that have been created at index time rather than calculating them on the fly during search time.
Search Term Synonyms – When not all your mistakes are spelling mistakes
We were quite happy with the way it worked then we typed in “goldcoast”… it couldn’t suggest Gold Coast, Queensland, Australia which is one of our top destinations.
Finally, we figured out we also wanted to be able to handle search term Synonyms. For example, our analytics data showed that a very common customer search term that was returning no results was “goldcoast” when a customer means to search for “gold coast”. This was not picked up as a phonetic match as the index has no way of knowing that the single word “goldcoast” should be two words. Instead, we needed to also add these known mistakes into our index in some way.
Azure Search does provide a way to do this in the form of Synonym Maps (https://docs.microsoft.com/en-us/azure/search/search-synonyms) that let you match any known mistake to a word which represents the correct way it is spelt instead. We opted not to in this circumstance as it would mean using a preview version of the Azure Search API.
We instead just created an additional field against each of our destination records which holds a collection of all possible mistakes for that destination. Such as “goldcoast” against our Gold Coast, Australia record. It turns out to be a much more manual process since we need to manage these synonyms for each destination record, however it allows us to maintain full control over which records will appear for each of these non-phonetic mistakes.
Onwards and Upwards – Hotel Name Searching
With our new search live and taking traffic, our team analysed stats, and found a significant percentage of our customers were searching for a specific hotel. Our current hotel listings are stored in thousands of JSON files which are hosted in Azure blob. With the knowledge we’d gained setting up our destination search and Azure Search’s JSON Indexing feature (https://docs.microsoft.com/en-us/azure/search/search-howto-index-json-blobs) we were able to quickly and painlessly add hotel data to our search index as well, something that would never have been possible in our old system. (Note: Azure Search blob indexing is currently still in Preview however, we accepted the risks as it did not affect the core functionality of autocomplete)
Hope this blog gave you guys a good understanding of our use of Azure search. At the start of the project no one on our team had ever used any of these technologies and it was a rewarding experience to deliver a new feature that help our customers and addressed Webjet’s needs.
We’ll be publishing more blogs on our journey, as we take to scalpel to our Monolith.
We gratefully thank Geoff Polzin, a senior consultant from Readify, for his contributions to this blog. Geoff was part of this journey too.